Master Thesis on “Egocentric Gaze Prediction via Self-Supervised Feature Forecasting”
Supervisor: Prof. Ville Kyrki (ville.kyrki@aalto.fi)
Advisor: Dr. Farzeen Munir (farzeen.munir@aalto.fi)
Keywords: Driver attention prediction, Computer vision, Multimodal learning, Gaze, Autonomous driving
Project Description
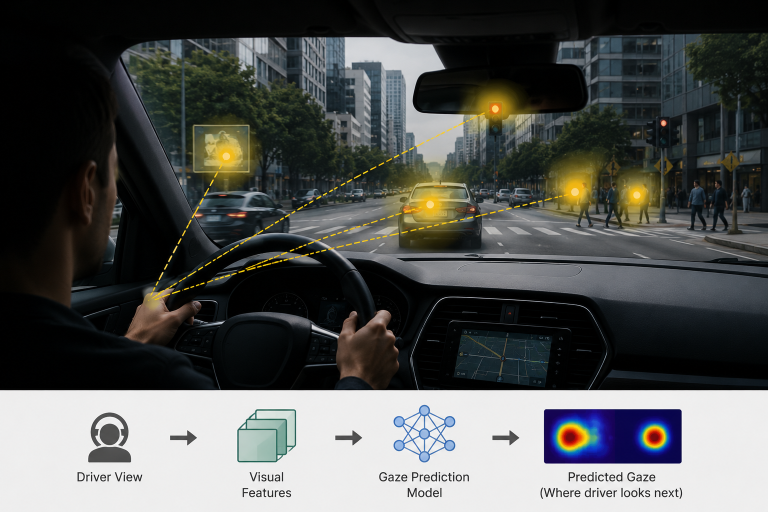
Predicting human gaze—especially in egocentric or driving scenarios—is fundamentally about modeling where people will attend next, not just where they are looking now. Existing approaches largely rely on current-frame saliency or short-term temporal cues, which limits their ability to capture the anticipatory nature of human attention. Recent advances such as DINO-Foresight demonstrate that it is possible to predict future semantic representations of a scene in a self-supervised manner, while works like Learning to Forecast Egocentric Video Attention and Transformer-based Visual Saliency Prediction highlight the importance of temporal modeling in gaze prediction. Building on these ideas, this thesis explores whether forecasting future visual features can improve gaze prediction by aligning models with the forward-looking nature of human perception, which is crucial for applications such as autonomous driving, assistive systems, and human–robot interaction.
The problem is challenging because gaze is influenced not only by visual stimuli but also by intent, task context, and latent scene dynamics, making it difficult to model purely from observable inputs. Moreover, predicted future features may not directly correspond to human attention, introducing a representation gap that must be bridged through careful model design and training. The student is expected to design and implement a pipeline that integrates feature forecasting with a gaze prediction module, conduct experiments on egocentric datasets, and systematically evaluate the benefits of future-aware representations. This includes understanding self-supervised learning, transformer-based architectures, and attention modeling, as well as critically analyzing results through ablations and comparisons with baselines. Key references include the DINO-Foresight project page, DINO-Foresight: Self-Supervised Feature Forecasting, Future Representation Learning for Video Understanding, and prior work on gaze prediction and visual attention modeling.
Deliverables
- State-of-the-art literature review on driver gaze prediction and attention modeling
- Development of a method for explainable driver gaze map prediction
- Experimental evaluation on benchmark datasets (e.g., DR(eye)VE, BDD-A)
- Analysis of interpretability and robustness of predicted gaze maps
Practical Information
Pre-requisites: Python(high), Deep Learning (high)
Tools: PyTorch
Start: Available immediately
References
- Where, What, Why: Towards Explainable Driver Attention Prediction (https://arxiv.org/html/2506.23088v1)
- DR(eye)VE: Predicting Driver Attention (https://arxiv.org/abs/1705.03854)
- DINO-Foresight: Self-Supervised Feature Forecasting (https://arxiv.org/abs/2412.11673)